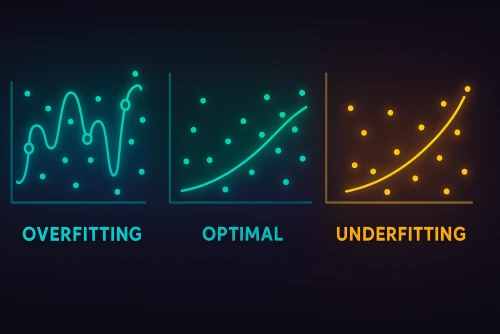
When you train a machine learning model, your goal is to create a model that not only performs well on the data it was trained on but, more importantly, generalizes well to new, unseen data. Two common pitfalls that prevent models from achieving this are Overfitting and Underfitting.
Understanding these concepts is crucial for diagnosing model performance issues and for building robust ML systems. They are closely related to the evaluation metrics you use to assess your model.
What is Underfitting?
Underfitting occurs when a model is too simple to capture the underlying patterns in the training data. It fails to learn the relationships between the input features and the output labels effectively.
- Characteristics:
- High error on the training data.
- High error on the test data.
- The model doesn't perform well even on the data it has seen.
- Analogy: Imagine a student who barely studies for an exam. They don't learn the material well enough and perform poorly on both practice questions (training data) and the actual exam (test data). Effective feature engineering can help by providing the model with more informative inputs.
- Visual Cue: If you plot the model's predictions against the actual values, an underfit model will often show a poor fit, missing the general trend of the data.
Causes of Underfitting:
- Model is too simple: Using a linear model for complex, non-linear data.
- Insufficient training: Not training the model for enough epochs (iterations).
- Features are not informative enough: The input features provided to the model don't have enough predictive power.
How to Address Underfitting:
- Use a more complex model: Try a model with more parameters or a different type of model (e.g., a polynomial regression instead of linear, or a deeper neural network).
- Feature engineering: Add more relevant features or create better features from existing ones.
- Train longer: Increase the number of training epochs (but be careful not to overfit!).
- Reduce regularization: If you're using regularization, try reducing its strength.
- Ensure you're using appropriate learning types: For instance, trying to use unsupervised learning techniques where supervised learning is needed.
What is Overfitting?
Overfitting occurs when a model learns the training data too well, including its noise and specific random fluctuations that are not representative of the true underlying patterns. The model essentially memorizes the training data instead of learning the general relationships.
- Characteristics:
- Very low error on the training data (the model performs exceptionally well on data it has seen).
- High error on the test data (the model performs poorly on new, unseen data).
- The model is too complex and has captured noise as if it were a real pattern.
- Analogy: Imagine a student who crams for an exam by memorizing the exact answers to specific practice questions. They might ace those specific questions (training data) but struggle when faced with slightly different questions on the actual exam (test data) because they didn't learn the underlying concepts.
- Visual Cue: An overfit model might show a line that wiggles and turns to pass through every single training data point, but this complex line wouldn't generalize well to new points.
Causes of Overfitting:
- Model is too complex: Using a model with too many parameters or too much flexibility for the amount of training data (e.g., a very deep decision tree or a neural network with too many layers/neurons for a small dataset).
- Insufficient training data: Not having enough data for the model to learn the true underlying patterns, so it starts learning the noise.
- Training for too long: Allowing the model to train for too many epochs can lead it to memorize the training set.
- High dimensionality (too many features): If you have many features, some might be irrelevant or noisy, and the model might try to fit them.
- Cross-validation: Use techniques like k-fold cross-validation to get a more robust estimate of how your model will perform on unseen data. This is a good practice even before considering specific ML algorithms.
How to Address Overfitting:
- Get more training data: This is often the best way to combat overfitting. More data helps the model learn the true signal from the noise.
- Use a simpler model: Choose a model with fewer parameters or less complexity.
- Early stopping: Monitor the model's performance on a separate validation set during training and stop training when performance on the validation set starts to degrade (even if training set performance is still improving).
- Regularization: Add a penalty term to the model's loss function that discourages overly complex models (e.g., L1 or L2 regularization for linear models, or dropout for neural networks).
- Cross-validation: A technique to estimate how well your model will generalize to unseen data by splitting your training data into multiple folds and training/testing on different combinations.
- Feature selection: Remove irrelevant or less important features.
- Data augmentation: For image data, create more training examples by applying transformations like rotations, flips, or zooms to existing images.
The Bias-Variance Trade-off
Underfitting and overfitting are closely related to the concept of the bias-variance trade-off in machine learning:
- Bias: The error due to overly simplistic assumptions in the learning algorithm. High bias can cause an algorithm to miss relevant relations between features and target outputs (underfitting).
- Variance: The error due to too much complexity in the learning algorithm. High variance can cause an algorithm to model the random noise in the training data, rather than the intended outputs (overfitting).
Ideally, you want to find a model with low bias (it can capture the true underlying patterns) and low variance (it generalizes well to new data). However, there's often a trade-off: decreasing bias tends to increase variance, and vice-versa. The goal is to find the sweet spot that minimizes the total error.
Finding the Balance
Achieving good model performance is about navigating this balance:
- Start with a relatively simple model and gradually increase complexity if it underfits.
- If your model overfits, try techniques like regularization, getting more data, or simplifying the model.
- Always evaluate your model on a separate test set (or use cross-validation) that was not used during training to get a true measure of its generalization ability.
Finding the right balance often involves experimenting with different model complexities, regularization techniques, and feature sets. This balance is key to building models that generalize well, which is a core theme in the future of machine learning trends.
Understanding overfitting and underfitting is a critical skill in the toolkit of any machine learning practitioner. By recognizing their signs and knowing how to address them, you can build more reliable and effective models.
What are your go-to strategies for dealing with overfitting or underfitting in your projects?
Comments